这是一篇关于 Cola DLM 的观点和看法的 blog。
我们想澄清一下我们的初衷:Cola DLM 的 motivation 从来不是 diffusion,而是 representation。
我们不是为了做 diffusion language model 才做 diffusion language model,而是想搞清楚一个更前置的问题——文本智能是否必须被绑在离散 token 上?如果不是,那么什么样的表征更适合承载语义、组织知识、支持生成,并最终连接到多模态环境?
论文地址:https://arxiv.org/abs/2605.06548
项目首页:Cola DLM — Continuous Latent Diffusion Language Model
一、核心论点:Cola DLM 不是"又一个 continuous DLM"
Cola DLM 的 diffusion 不是在恢复 token,而是在 transport 一个 latent prior。
这一点在 paper 里有非常严格的概率定义。Cola DLM 的生成模型只由两件东西组成:
- $p_\psi(z_0)$ 是 latent prior,由一个 block-causal DiT 通过 Flow Matching 学得;
- $p_\theta(x \mid z_0)$ 是 conditional decoder,负责把 latent 实现为具体文本;
- 训练时引入的 $q_\phi(z_0 \mid x)$ 只是 variational encoder,不是生成模型的一部分。
它实际跑的 stochastic path 是:
这条路径里没有 token。Token 只出现在最后由 decoder 实现的一步,Flow Matching 学的是从 $\mathcal{N}(0, I)$ 到 latent prior 的 transport map,不是某条"从噪声 token 到干净 token"的 denoising 轨迹。
这一点正是 Cola DLM 与大多数 continuous DLM 的根本切入点差异。一些其他的相关工作主要在 token 的状态空间上做 observation recovery(当然也有一些和我们类似的方法)。Cola DLM 把 diffusion 移到了 latent 层做 prior transport,把 token 完全交给 decoder。这不是包装上的差异,而是改变了 diffusion 在模型里到底干什么。
二、问题的起点:Token-level 不一定是最优状态空间
先给一个暴论:Token 是人类语言系统的表层载体,不是语义本身。
主流 autoregressive language model 的形式是:
它非常成功,但它隐含了一个挺强的状态空间假设:模型的内部状态被绑定在 surface token prefix 上——全局语义规划与局部词面实现,必须共同走完整的、单向的、逐 token 的 filtration。
只要稍微想一想就能感受到 token 不等于语义:
- 中文:我今天很开心。
- 英文:I am very happy today.
- 法文:Je suis très heureux aujourd'hui.
三种语言的 token、词表、语法、局部结构完全不同,但背后的语义、情绪、时间条件几乎一致。同一种语言里也是一样:
- 我今天很开心。
- 今天我心情很好。
- 今天过得挺愉快。
token 差了一大堆,语义还是那一个。
如果模型只把文本看成 token 序列,那么对每一种 surface form 都要单独学一堆局部条件概率;但如果存在一个更稳定、更压缩的 latent semantic state,那这些 paraphrase 本可以在模型内部映射到接近的同一个状态。
所以 Cola DLM 想问的第一个问题是:
我们的回答是:不一定。Token 是历史演化和工程 tokenizer 的产物,但模型内部不一定要继承这种粒度。真正重要的是表征,token 只是表征 realize 出来的一种形式而已。
这也正是 multi-token prediction(MTP)这条技术路线值得被重新理解的地方。MTP 不应该只被当作一次预测多个 token 的推理加速技巧。更本质地讲,它在挑战一次语义计算是否必须对应一个 token 这个假设。如果两个、多个甚至可变长度的 token span 背后共享一个更稳定的 semantic chunk,那模型就完全没有义务在最细的 token 粒度上组织所有信息。Cola DLM 的分层 latent,就是在同一个方向上更进一步:不是只预测多个 token,而是先学习能承载多个 token 背后语义的 latent state。
三、解法:把语义和实现分层
如果数据里存在低维但高价值的全局语义结构,最自然的建模方式是把它拆成 latent prior + conditional decoder 两层。
形式化地说,假设真实生成过程长这样:
其中 $g$ 是某个全局语义变量。它不必是显式 topic,也不必是单个向量,可以是一个高维、结构化、连续的 latent semantic state。
那么文本生成可以被分成两件相对可分的事:
AR 模型把这两件事压到同一条 token chain 上,让全局语义规划、局部词面选择、语法实现、长程依赖和信息压缩都通过同一个 left-to-right prefix filtration 传播。Cola DLM 则把它们拆成两个明确的子模块:
- prior $p_\psi(z_0)$ 学 $g$ 的分布;
- decoder $p_\theta(x \mid z_0)$ 学 $x \mid g$ 的 realization。
这里最关键的一点是:$z_0$ 不是 token embedding 的简单替代,而是一个显式参与边缘化的随机变量。Cola DLM 的建模对象因此从
变成
也是因为这一点,paper 在写作上有意弱化"continuous DLM"作为主要 contribution,而更强调 latent / hierarchical / prior。Continuous 是表征空间的性质,diffusion 是 prior learning 的工具,真正的问题是:什么 latent state 更适合承载语言?
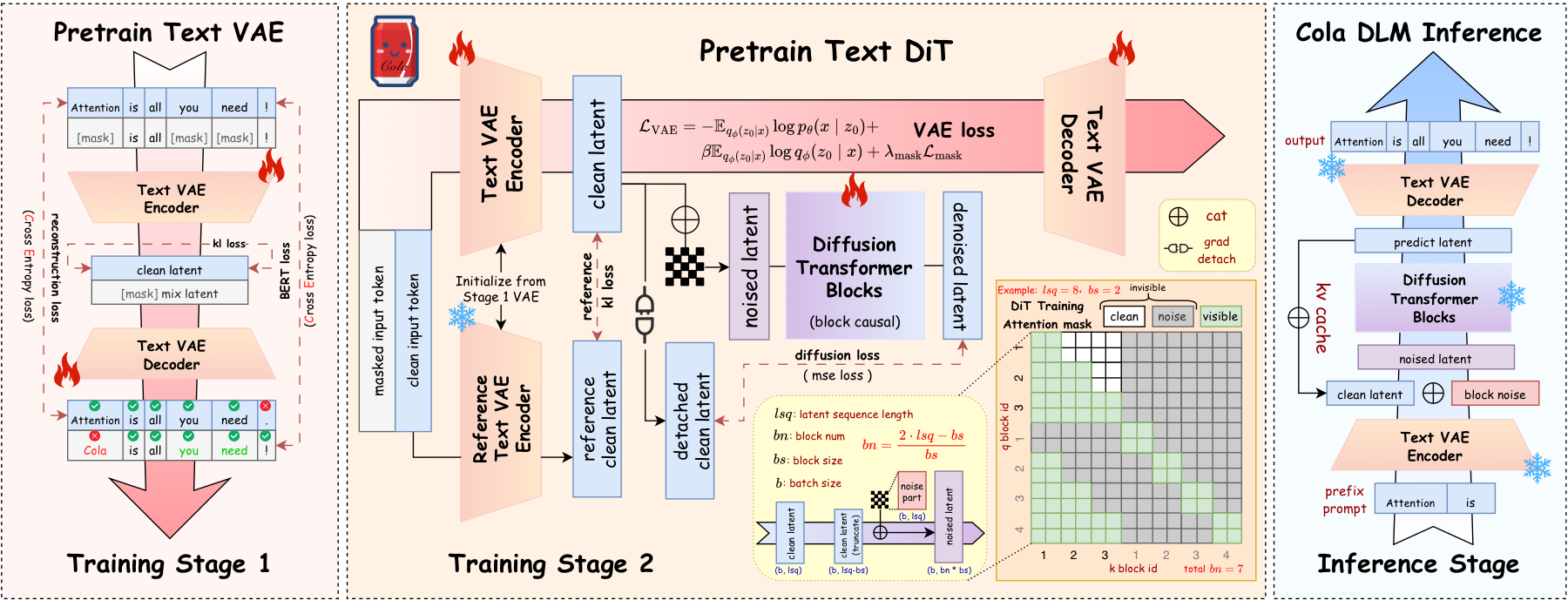
Cola DLM 整体 pipeline(Text VAE → Block-causal DiT → Conditional Decoder)如下图——注意 diffusion / DiT 是作用在 latent 上的 prior 模块,不是在 token 上做 denoising。
四、ELBO 信息分解:这个框架到底在优化什么?
Cola DLM 的训练,从一开始就不是单纯的 token-level likelihood fitting。
为了避免只停留在直觉层面,我们看一下 Cola DLM 的平均 ELBO 长什么样。对任意文本 $x$,由 Jensen 不等式:
定义 aggregated posterior
以及 joint $q(x, z_0) = p_{\mathrm{data}}(x)\, q_\phi(z_0 \mid x)$。则数据平均 ELBO 可以被改写成一个非常干净的三段分解:
这三项每一项都是可以单独读懂、单独诊断的:
- Conditional realization:$\mathbb{E}_{q(x,z_0)}[\log p_\theta(x \mid z_0)]$。decoder 在 latent 给定时能不能把文本写出来。
- Information compression:$I_q(X; Z_0)$。latent 里到底装了多少关于原文本的信息。这就是 latent bottleneck 的"率"。这个量太小,latent 承载不了足够语义;太大,latent 会退化为近乎逐 token 的记忆,失去抽象和压缩。
- Prior matching:$\mathrm{KL}(\bar q_\phi(z_0)\,\|\,p_\psi(z_0))$。learned prior 是否能拟合 encoder 在真实数据上诱导出的 aggregated latent distribution。
当 encoder 和 decoder 固定时,prior learning 退化成
所以,Cola DLM 想优化的 text modeling 是一个由 representation、compression、prior matching、realization 共同组成的分层问题。它把单一的 token-level likelihood fitting 拆开了,让我们能在不同子目标上分别去诊断和改进。
五、什么时候分层值得做:rate-distortion 的判据
Cola DLM 的优势不是由"用了 latent"或"用了 diffusion"自动保证的,它的成立有一个可被检验的前提。
我们可以用 representation rate-distortion 的语言把这件事说严格。定义
它表示:当 latent channel 最多允许传输 $R$ nats 的信息时,最小可达到的重建代价是多少。
如果 $D(R)$ 在较小的 $R$ 上就已经很低,说明数据中存在低率但高价值的表征——大量 token-level detail 未必是生成高质量语义所必须的;真正决定生成质量的,是某些更抽象、更稳定、更可迁移的全局语义变量。这种情况下 latent bottleneck 反而有利。
反过来,如果只有 $R \to H(X)$ 时 $D(R)$ 才下降,说明文本几乎不可压缩,局部形式本身承载主要语义,这时强行压缩 latent 只会使条件重建更难。
更形式化的"结构性生成假设"是:
如果这个结构成立,那 Cola DLM 的分层就贴近真实生成机制:prior 学 $p^\star(g)$,decoder 学 $p^\star(x \mid g)$。
也就是说:Cola DLM 的判据不是"用了 diffusion",而是"文本分布是否真的具有低维全局语义结构"。这是一个可被实验回答的问题。下一节的 RQ1 实验,我们尝试通过反证法去给出存在性证明。
六、Latent 中真的存在共享语义结构吗:RQ1 的反证式论证
RQ1 不是普通的 ablation,而是在回答整套理论的支点问题——latent space 是否真的存在低维共享语义结构,还是只是 token 的连续替身。
我们没有直接去证明语义结构存在,因为这件事天然难以严格证明。我们采用的策略是构造一个反证零假设(这里受到 stable diffusion 3 的 paper 中相关 noise schedule 和 logSNR 章节的启发):
假设 latent representation 是纯局部、纯可分的:每个 latent dimension 独立贡献语义;改变 latent dimension 只是在增加独立局部单元的数量,而不会改变语义恢复所需要的时间尺度。
这个零假设可以写成形式化命题。设 $d$ 为 latent dimension,$\delta$ 为 timestep shift(noise schedule location),$J_d(\delta)$ 为某个语义评价指标。如果 latent 是纯局部可分且同质的,那么一定可以写成
如果进一步假设每个局部维度同质,那存在公共 $j(\delta)$ 与正常数 $a_d > 0,\, b_d \in \mathbb{R}$,使得
由于 $b_d$ 与 $\delta$ 无关、$a_d$ 只是正比例缩放,立刻得到
也就是说:纯局部可分假设下,最优 timestep shift 不应该随 latent dimension 系统漂移。
逻辑结构很清楚:
按逆否命题,如果实验里观察到 $\delta^\star(d)$ 随 $d$ 稳定、单调、可复现地漂移,那这个零假设就被否掉了。
RQ1 的实验现象非常清楚:通过扫不同 latent dimension 下的 timestep shift,看语义任务表现的峰值位置(Task Avg),结果大致是
这个 drift 是近似单调的;并且 LAMBADA、MMLU、SIQA、Task Avg 都共同支持"latent dimension 越大 → 偏好越大的 loc 区域"。也就是说,peak shift 不是某个 benchmark 的偶然抖动,而是跨多个语义任务一致出现的现象。
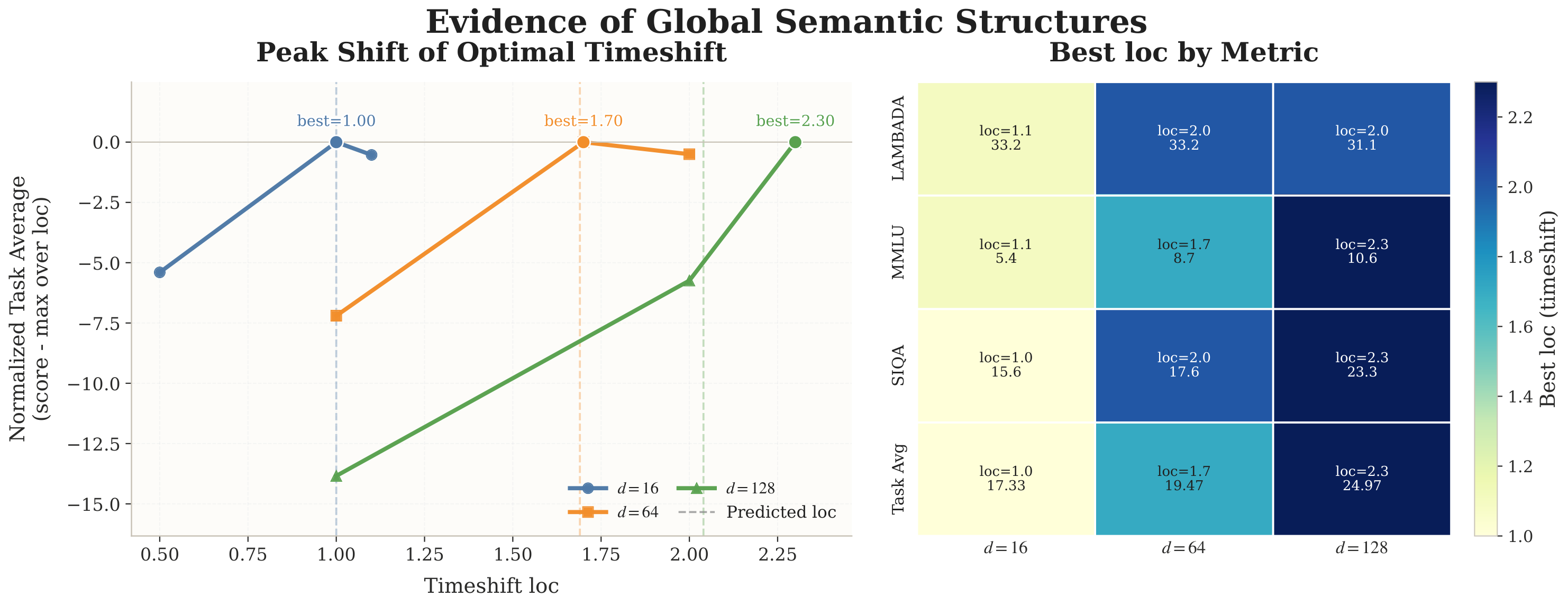
需要严谨地说明一下这组实验证明了什么、没证明什么:
它没有证明"latent space 中存在唯一可命名的语义变量 $G$"——那是一个更强的结论,paper 也没敢这么说。它支持的是一个更弱、也更可靠的结论:
Latent representation 不是纯局部可分的,其中存在会影响语义指标的跨维度共享结构。
这已经够支撑 Cola DLM 的全部出发点了:latent 里有一个值得被 $p_\psi$ 去建模的共享结构。RQ1 实验看起来很显然,但是给出了很严格的存在性依据,让我们有信心继续做相关 scaling 实验。
七、为什么是连续:因为语义本身具有几何结构
Continuous 不是为了赶时髦,而是因为语义关系本身具有平滑的几何。
这一节最容易被误读为"连续 > 离散",所以我先把话说在前面:不是连续一定比离散高级,而是说当我们想建模的是语义空间的几何结构时,连续空间提供了更自然的工具。
举两个最直观的例子:
- "猫坐在沙发上"
- "小猫躺在沙发上"
两句话在 token 上差异明显,但语义上很接近。反过来:
- "I have a cat."
- "I hate a cat."
只差一个 token,语义已经完全反了。Token edit distance 跟 semantic distance 是两套尺度,硬把语义建模建立在 token 离散 simplex 上,要让它学到语义平滑性就得绕弯子。
一个合理的 latent space 至少应该弱满足某种语义平滑性:
更理想地,也希望弱逆关系成立:
这种几何关系在离散 token simplex 上很难自然表达;但在连续 latent 上可以用 interpolation、local perturbation、Gaussian smoothing、logSNR calibration、vector field transport 这些工具直接刻画。
所以"连续"在 Cola DLM 中不是我们的目的,而是一个性质良好的表征形式:
- 我们想要的是一个能承载语义几何的表征;
- "连续"是这种几何最自然的载体;
- "连续"反过来又决定了 prior 适合用什么工具——这就把我们引到了 diffusion / flow matching。
八、为什么用 Diffusion / Flow Matching:它是 solver,不是 motivation
Flow Matching 在 Cola DLM 里是"建模连续 latent prior 的求解器",不是"diffusion language model 的定义"。
让我们沿着上一节的逻辑往下走。一旦表征是连续的,prior learning 要解的问题就是
而 $\bar q_\phi(z_0)$ 一般不是高斯。它带着 RQ1 揭示出来的那种跨维度共享结构,是一个真正复杂的连续分布。要把一个简单分布($\mathcal{N}(0,I)$)变成它,最自然的工具就是 continuous-time flow / diffusion:
具体实现上,Cola DLM 把 latent 切成 blocks,做 block-causal 因式分解:
每个 block 上学一个 conditional Flow Matching objective:
Block 内是双向 attention,block 间是 causal——这同时拿到了"块内并行 denoising"和"跨块 causal 推进"两件事。
但需要澄清的是,Flow Matching 在 Cola DLM 里只是 solver:
Flow Matching is a solver for latent prior learning, not the definition of the model itself.
把它换成 rectified flow、NF、shortcut model、consistency model、甚至 autoregressive latent prior,理论上都不会破坏 Cola DLM 的核心结构——因为这一层只负责把简单 noise 分布 transport 成 latent 上的目标分布。Cola DLM 不会因此变成另一个模型。
九、Text VAE 而不是只用 embedding:因为我们要一个显式 latent variable
Embedding 也是一种连续表征,但它仍然是 token-aligned 的。Cola DLM 需要的是一个能参与 marginalization 的显式 latent variable。
去年我们就尝试过在 token embedding space 上做 flow 的方案。它当然是连续的,但有两个根本性局限:
- Token-aligned:每个 token 仍然有一个 embedding,模型基本单位仍然是 token。它跑的是在连续空间里恢复 token-aligned 观测,而不是建模一个全局可压缩 state 的生成分布。
- 没有显式 latent-variable 的概率解释:缺少
$$p(x) = \int p_\theta(x \mid z_0)\, p_\psi(z_0)\, dz_0$$ 这个 marginal 结构,也就拿不到 ELBO 那三项分解,自然没法分别讨论 representation / compression / prior。同时我们没有理论依据去验证连续的特性就能超过离散(或许这是一个值得探讨的点),但是 Cola DLM 给出了超过 AR 等离散方法的理论依据。
Cola DLM 用 Text VAE 是因为它提供了一个从离散文本到连续 latent 的概率接口:
- encoder $q_\phi(z_0 \mid x)$:把文本 lift 到 latent 分布;
- decoder $p_\theta(x \mid z_0)$:把 latent 实现为文本;
- prior $p_\psi(z_0)$:拟合 aggregated posterior 上的生成分布。
这并不意味着 VAE 是唯一选择——paper 的 Future Prospects 里也写得很清楚:未来可以换成更强的 AE、RAE、BERT/T5-style semantic encoder,甚至 multilingual shared encoder。关键不是 VAE 本身,而是是否能稳定地提供一个可生成、可压缩、语义组织良好的 latent space(表征)。
十、统一 Markov-path 视角:和其他 continuous DLM 的切入点差异
LLaDA / Plaid 改的是 token / token-aligned 状态上的 corruption-recovery 过程,而 Cola DLM 改的是"diffusion 在模型里到底干什么"。
paper 给了一个很清晰的统一 stochastic-path 视角。把任意 process-based 生成模型写成
这个统一外形不决定模型本质。真正区分模型的是 path 的状态空间,以及它的语义角色:在文本或近无损的 text-aligned representation 上跑的,是 observation path;只用来生成 latent prior 的,是 prior path。
| 模型 | 状态空间 | 路径角色 | 生成因式分解 | 连续性出现在 | 显式 latent |
|---|---|---|---|---|---|
| AR | Prefix Tokens | Direct Generation Path | $\prod_i p(x_i \mid x_{<i})$ | 无 | 否 |
| LLaDA | Discrete Masked Sequences | Discrete Observation-Recovery | $p(s_T) \prod_t p_\theta(s_{t-1} \mid s_t)$ | 离散 token space | 否 |
| Plaid | Continuous Token-Aligned Reps | Continuous Observation-Recovery | $p(h_T) \prod_t p_\theta(h_{t-1} \mid h_t)$ | 连续 token space | 否 |
| Cola DLM | Compressed Latent Sequences | Prior-Transport Path | $\int p_\theta(x \mid z_0)\, p_\psi(z_0)\, dz_0$ | Latent Space | 是 |
LLaDA 把 AR 的左到右先验松开了,但它仍然在离散 token state 上做 corruption-recovery。Plaid 把这件事搬到 token-aligned 的连续 representation 上做,但目标仍然是 observation recovery。Cola DLM 是另一件事——它在 latent 上 transport 一个 prior,token 由 decoder 一次性输出。
也正因如此,paper 在 unified-criterion 一节给出的判据,是一个把 model approximation error 和 variational inference gap 都算进去的总损失:
Cola DLM 优于一个对照模型,当且仅当它的总统计负担更小。例如对 AR:
所以 Cola DLM 是不是优势,最终由三条曲线决定:
这表明严格意义上来讲,diffusion 或 continuity 都不会自动带来收益,它要建立在数据本身具有低维全局语义 + 高维局部 token realization 这种结构性的前提上。
十一、训练里的关键事实:fixed vs joint,BERT loss,VAE logSNR
Latent space 既不能训死了不动,也不能从零放飞自己。它需要从稳定初始化出发,受控地与 prior 共同演化。
paper 把 Cola DLM 的训练拆成两阶段。
Stage 1:Text VAE pretraining。建立 stable latent–text correspondence。损失是
这里那个 BERT-style mask loss 不是装饰——它在 stage 2 里非常重要,作用是防止 VAE encoder 在 reconstruction 压力下"语义坍塌",让 encoder 不只是为 reconstruction 服务,而是保留可用的局部语义结构。
Stage 2:Block-causal DiT prior learning。visible set 是
这里的 $\operatorname{sg}(\cdot)$(stop-gradient)很关键:它防止 diffusion loss 直接 hack encoder,导致 latent collapse。
Stage 2 的总损失把 VAE preservation、FM prior、reference regularizer 组合起来:
这不是 VAE / DiT / decoder 的机械拼接,而是受控的 co-adaptation:encoder reshape latent 分布,prior 反过来 regularize 它,decoder 保持 textual realization 的能力。reference regularizer 一项专门用于压制 latent drift。
RQ2 给出了几个非常具体、也非常一致的结论:
(1) Fixed vs Evolving Latent。在同一 compute 预算下比较 Fix VAE / Joint DiT x1 / Joint DiT x0.01 / All Scratch x1 / Interval:
- 小 compute 下 Fix VAE 还能跟得上甚至略好;
- 大 compute 下 Joint DiT x1 持续向上、最终在 Task Avg、LAMBADA、MMLU、SIQA 都拿到最优,而 Fix VAE 逐渐饱和;
- All Scratch x1 一路最差——这说明"latent 可训"不是优势的本质,优势来自"从一个有意义的预训练 latent 出发再 co-adapt";
- Joint DiT x0.01 和 Interval 都不如 Joint DiT x1,说明 latent 更新强度不够、或者周期性冻结都会破坏协同演化。
可视化可以看到从零联训得到的 latent 几何更坍塌、轨迹更单调,带稳定初始化的 joint 训练得到的 latent 更结构化、更语义化。我们最近还有一些尝试,对 joint training 有更深入的认识,欢迎关注后续的工作!
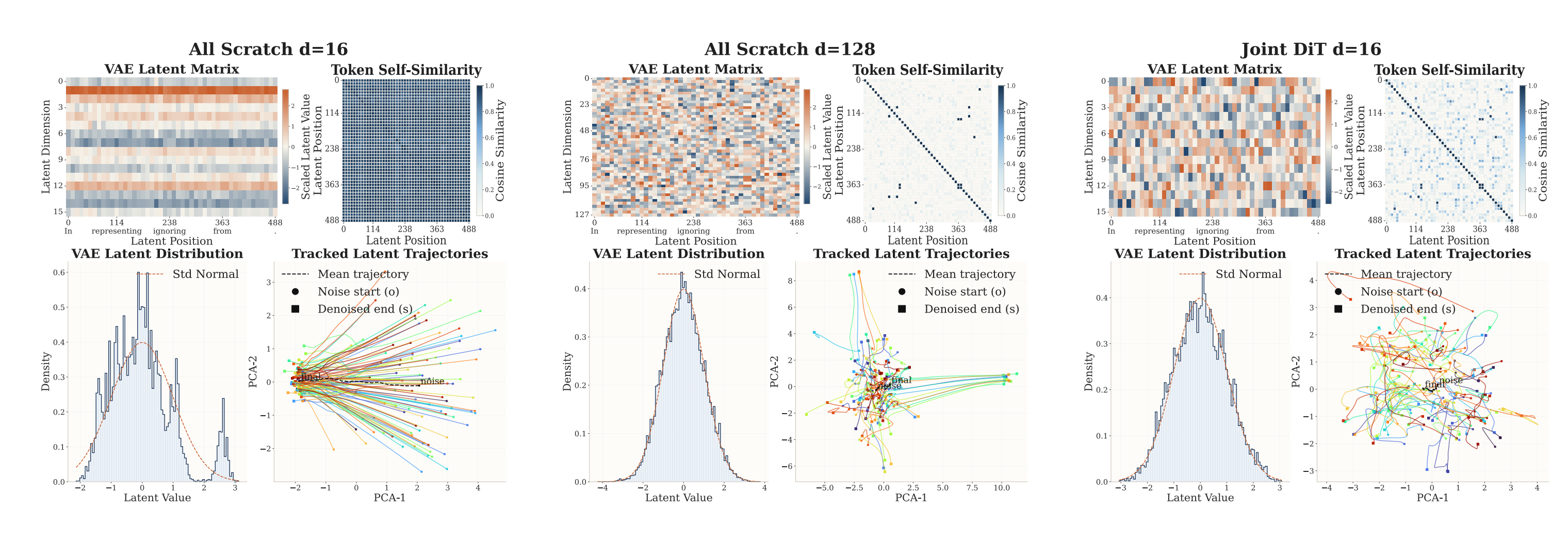
(2) Latent Dimension。在 117 EFLOPs 的 All Scratch ablation 下:
| Method | LAMBADA | MMLU | SIQA | Avg. |
|---|---|---|---|---|
| All Scratch, $d=16$, loc=1 | 14.3 | 6.9 | 4.9 | 8.7 |
| All Scratch, $d=64$, loc=1 | 20.9 | 5.4 | 7.6 | 11.3 |
| All Scratch, $d=128$, loc=1 | 18.5 | 8.1 | 8.9 | 11.8 |
平均分从 $d=16$ 的 8.7 一路涨到 $d=128$ 的 11.8。结合 RQ1 的 drift 看:latent dim 不是单纯放大空间,它还在改变语义信息在 logSNR 轴上的最佳恢复位置。这也是 paper 反复强调"latent dim、VAE logSNR、noise schedule 不是独立超参,而是共同作用于 effective mutual-information curve"的原因。
(3) BERT-style loss 与 semantic smoothness。在 Joint DiT 设置下,加 BERT loss 一致地优于不加;尤其当 VAE 的学习率比例 $=1$(更主动的 latent 更新)时,BERT loss 带来的提升最明显。"只让 latent 能动"远远不够,必须给它一个语义约束,否则它可能只是为了降 diffusion / reconstruction loss 而漂走。
(4) VAE logSNR。在 77.86 / 116.78 EFLOPs 两个 budget 上,learnable VAE logSNR(学习后 $\approx 4.5$)综合最强;fixed VAE logSNR = 1.5 是最好的固定替代。VAE logSNR 控制的是 latent probability space 的局部平滑度,它和"语义平滑度"是两件事——这一点会在 PPL 那一节再展开。
总结来看:
Latent space 是 Cola DLM 的核心对象。它不是固定的、不是随便训的,它需要从稳定 init 出发、被语义约束(BERT loss)、被合适的 logSNR 校准,并在 joint training 中和 prior 一起演化。
十二、Diffusion 端的调参逻辑:block size、noise schedule、推理步数、CFG
RQ3 的所有调参,本质上都在做同一件事——把 denoising 轨迹和 latent 上语义信息的曲线对齐。
我把 RQ3 的关键结论按"训练侧 / 推理侧"汇总,然后给一个统一的解释。
(1) DiT Block Size。在 30k / 40k checkpoints 上扫 block size = 1, 16, 64, 128:
- $\text{block} = 16$ 在两个 checkpoint 上的 Task Avg 都最高,LAMBADA、MMLU 表现尤其稳;
- $\text{block} = 64, 128$ 在所有任务上都明显退化;
- $\text{block} = 1$(接近 fully causal token-level processing)比 64/128 强,但仍不如 16。
读法:block size 不是普通工程参数,它在调"局部 realization 粒度 vs 全局语义聚合"的折中。过小,模型退化为逐 token 因果,丢掉了 block 内并行 attention 的好处;过大,块内局部交互被稀释,语义聚合反而受损。
(2) Noise Schedule。扫 schedule location $\mathrm{loc} \in \{0, 1, 2, 3, \dots\}$ + uniform:
- $\mathrm{loc} = 1.0$ 在 30k / 40k 都拿到最高 Task Avg,MMLU、SIQA 提升尤其明显;
- $\mathrm{loc} = 0$ 或 uniform 一路偏弱;
- Joint DiT × $\mathrm{loc} = 1$ 最终能匹配甚至超过 Fix VAE 的对应基线,而 mismatch 的 schedule 做不到这一点。
为什么 schedule 这么"敏感"?paper 在附录里给出了 implication:改 schedule location 就是在挪 logSNR 轨迹,进而改变 DiT 在不同 diffusion time 上看到多少语义信息。所以"最佳 schedule"应当被理解为:
也正因如此,最优 schedule 跟 latent dim、VAE logSNR、block size 都耦合——RQ1 那个 drift 现象本质上也是这个耦合的一个侧面表现。
(3) 推理步数。1–2 步基本不能用;到 8–10 步主要性能已经恢复;16–32 步基本饱和。因为 block size = 16,所以 8–10 步意味着每 16 个 text token 大约需要 8–10 次顺序 denoising —— 相对 AR 在序列深度上有 1.6–2.0× 的等价压缩。
(4) CFG。典型的非单调曲线。Task Avg 从 0 快速上升到 3–6 区间到顶,之后开始下降;超过 10 后明显劣化,到 20、60 严重退化。Excessive CFG distorts the denoising trajectory rather than improves it —— 这跟 image diffusion 上的经验也一致。
最终 paper 在 RQ4 里 lock 的"最优配置"是:
但是实际上我们在后续实验发现,latent dim 变大,并且找到合适的 logSNR 后,能够具备更强的表现,也欢迎大家尝试。
十三、Scaling 实验
Cola DLM 在 ~2B 参数、~2000 EFLOPs、严格匹配的对比下,hierarchical continuous latent prior modeling 表现出有意义的 scaling 趋势。
- 在严格匹配下(AR、LLaDA、Cola DLM 的非 embedding backbone 都约 1.8B,加 embedding 约 2B 总参数)独立训练 baseline。Cola DLM 用约 500M VAE + 1.8B DiT;AR 和 LLaDA 的非 embedding backbone 也控制在约 1.8B;
- 全部模型在统一的 few-shot generative protocol 下评估:LAMBADA、SQuAD 当 generative task;其余多选题也 cast 成 few-shot 生成;
- scaling 曲线一直到约 2000 EFLOPs。
结果是:
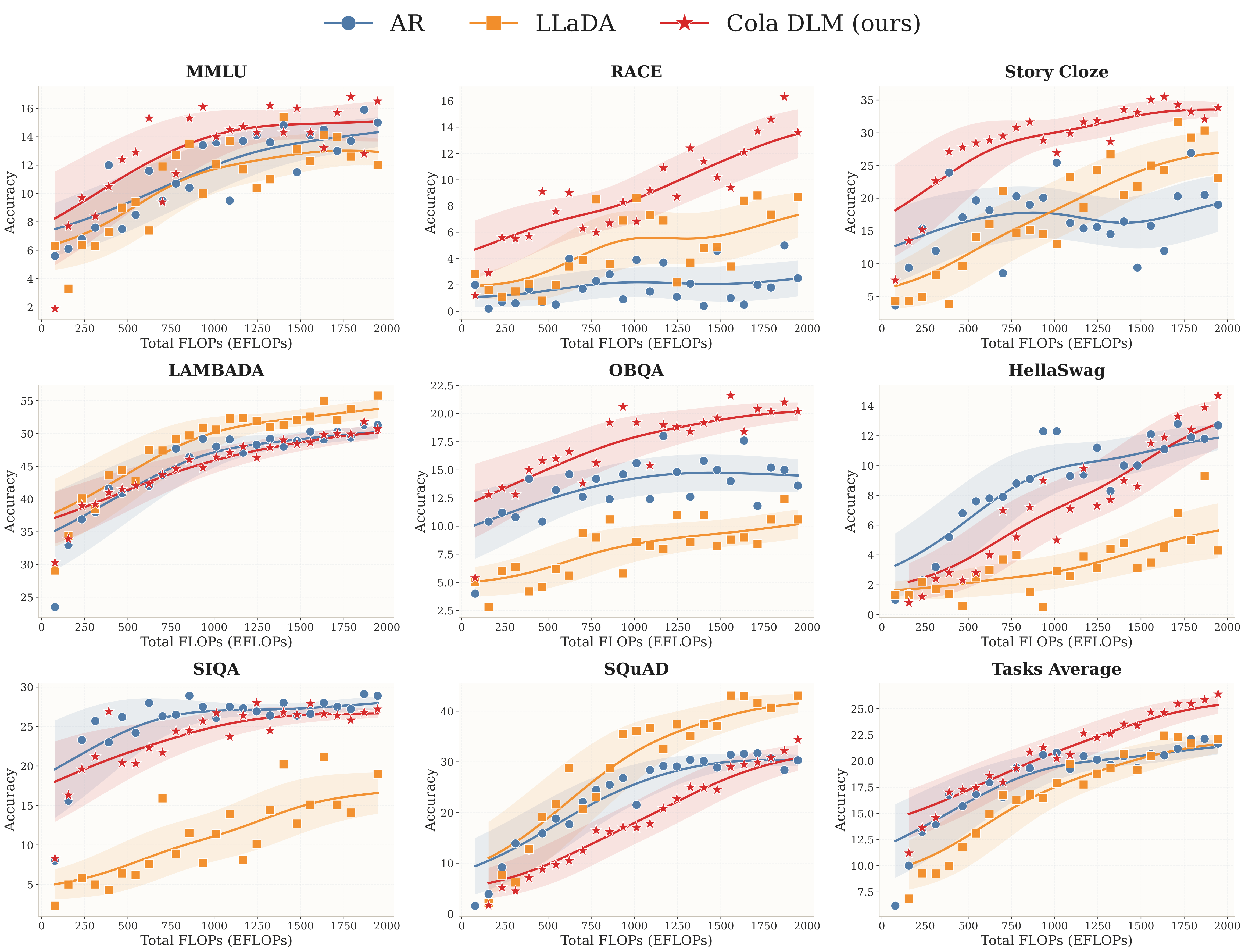
- Task Avg 上 Cola DLM 表现出最稳的上升趋势,在大 compute 区间拿到最优;
- 在更依赖全局语义组织和 reasoning 的任务(MMLU、RACE、Story Cloze、OBQA)上,Cola DLM 的 mid-to-late scaling 优势尤其明显;
- 在生成型任务(LAMBADA、SQuAD)上,Cola DLM 的 scaling 行为与 AR / LLaDA 相当或更好——SQuAD 大 budget 区间甚至超过 AR 并逼近 LLaDA 的强表现区。
但这里有一点必须诚实地说出来:多选题上"绝对分数偏低"是统一 generative protocol 的预期结果,而不是模型能力上限(我们受限于计算资源,后续也将努力训出一个工业级模型供大家使用)。在 likelihood-based discriminative 设置下,绝对值会不一样;但要做严格、对所有模型一视同仁的对比,generative protocol 才是公平的。paper 在 RQ4 里特意写了这件事,理由我们在下一节展开。
而且这一组配置本身就保守:
- latent dim 只用了 $d = 16$(RQ2 已经显示 $d = 64, 128$ 在 117 EFLOPs 下有明显提升空间);
- compression 还没解决边界对齐问题(见后文 patch 实验);
- VAE logSNR、noise schedule、block size 的联合 calibration 还有大量空间;
- Text VAE 不是最终形态,可以换更强的 representation model;
- 数据规模和训练规模都没有触及更工业级的上限。
十四、PPL 不再是新范式下的最优评价语言
在 Cola DLM 里,generation quality 和 likelihood-oriented PPL 之间存在一个结构性 gap,而这个 gap 不是 bug,是新 representation 的自然产物。
要把这件事说清楚,先看两个量。对于 prefix–response 切分 $x = (x^{\mathrm{pre}}, x^{\mathrm{res}})$,response 的真正条件 marginal 是
而我们实际能拿到的局部 score 是
前者只要 prior mass 到达"decoder-valid"的语义区域,就能生成合理文本;后者要求 prior density 在 ground-truth posterior 邻域附近做精确局部 calibration。两个目标不是同一件事。
这件事不是 hand-waving,paper 在 discussion 里给了非常具体的 token-level 反例。看一段文本里的 ground-truth token at:
- Direct training(unfixed VAE logSNR ≈ 4.5)下,likelihood-derived PPL = $1.15 \times 10^6$,generated token 是
on; - Fixed VAE logSNR = 1.0 下,PPL 暴跌到 641.57,generated token 是
in; - Fixed VAE logSNR = 1.5 下,PPL 245.36,generated token 是
,。
PPL 越低,反而生成得越差。再看 her 这个 token:direct training 的 PPL 高得离谱($6.93 \times 10^8$),但 generated token 就是 her,generation PPL = 1.12。
Generation 跟 latent space 的语义平滑度更相关;likelihood-oriented PPL 跟 VAE logSNR 决定的概率空间平滑度更相关。这两种 smoothness 不是同一种 smoothness。
更直观地,下图展示了同一个 ground-truth token 周围 latent geometry 与 prior-density landscape 的对比:decoder probe success 与 posterior hit 都很高,说明 decoder 能在 posterior 邻域稳定恢复;但 prior hit 与 density alignment 跨样本剧烈变化,意味着主要 issue 不是 decoder 失败,而是 prior 在 gold latent 周围的局部 calibration 漂移。
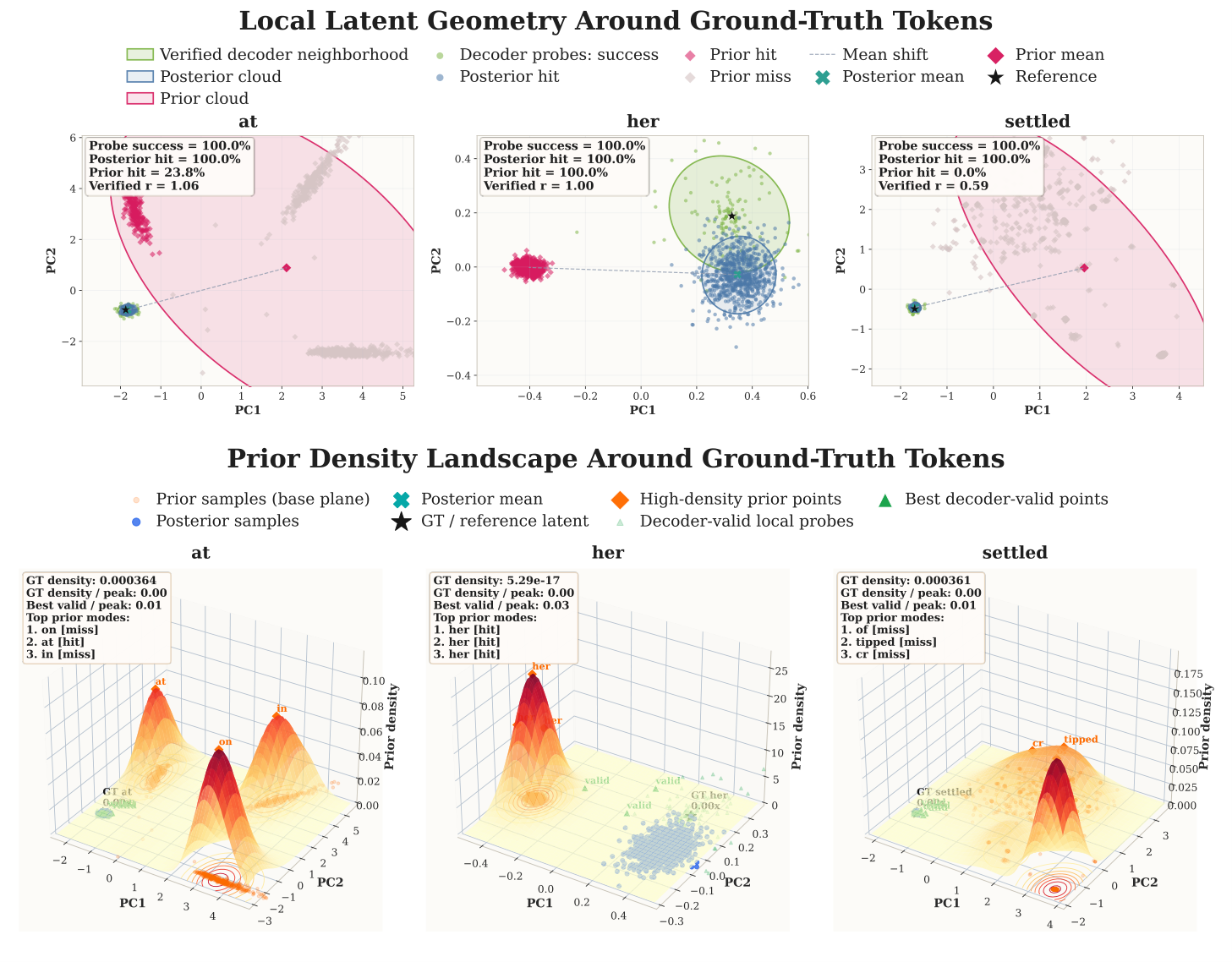
这就是为什么 Cola DLM 在 RQ4 里强调要用 unified few-shot generative protocol——不是为了绕开 PPL 不利的事实,而是因为 PPL 在这种 representation/objective 改变后的范式里,不再是和真实生成能力对齐的指标。
更普遍地讲:当你 change representation,你必须 change evaluation language。这是 representation-centric thinking 的一个推论,而不是 Cola DLM 的特例。
十五、Token 粒度不一定是最优粒度:patch 实验的一个有趣信号
当前 token 切分未必是语义最高效的载体;只要解决了边界对齐,"用更少 latent 表达更多 token"反而可能更好。
paper 的 discussion 里做了一个 compression 实验:同 latent dim ($d = 128$),对比 patch size 1(每 token 一个 latent)vs patch size 2(每两个 token 一个 latent):
| Sample Label | Overall p1 | Overall p2 | Mod0 p1 | Mod0 p2 | Mod1 p1 | Mod1 p2 |
|---|---|---|---|---|---|---|
| LAMBADA | 31.10 | 17.40 | 32.11 | 34.55 | 30.12 | 0.79 |
| MMLU | 5.40 | 3.90 | 6.89 | 7.68 | 3.86 | 0.00 |
| SIQA | 11.10 | 6.10 | 12.92 | 12.13 | 9.26 | 0.00 |
| Avg. | 15.87 | 9.13 | 17.31 | 18.12 | 14.41 | 0.26 |
直觉上把两个 token 压成一个 latent 应该会丢信息。但实际上:
- Overall p2 是比 p1 弱不少;
- 但拆开看,几乎所有的劣势都来自 Prompt Len Mod1(prompt 长度不能被 patch size 整除的情况);
- 一旦只看 Prompt Len Mod0(能被 2 整除)的样本,p2 反而在平均上略优于 p1(18.12 vs 17.31)。
也就是说,当前 p2 整体偏弱主要不是因为 compression 本身,而是因为 boundary misalignment:当 prompt 长度不能被 patch size 整除时,prompt latent 会被语义地挪位,而这个 prompt latent 又恰好是后续 block-wise prior 的 clean condition,它一旦偏,所有后续生成都偏。
这是一个非常有启发意义的信号:
- token-level 切分不一定是最优粒度;
- 若 latent grouping 是语义有效的,那么"每个 latent 对应更大的 textual span"反而更贴近 prior 的本职——组织全局语义,而不是承担逐 token 重建;
- 工程上,这种压缩还顺手让 sampling 更高效(patch=2 时同样的 block size = 16 已经能覆盖 32 个文本 token)。
未来值得探索的方向是清楚的:adaptive segmentation、learned boundary scorer、variable-length latent chunks、phrase / event-level pooling、hierarchical latent pyramids……总之,一个 token 一个 latent 这个约束没必要硬绑。这件事和第二节里 MTP 的逻辑是一脉相承的,建模单位不必停在 token 上。
十六、未来方向:探索更好的文本表征形态
Cola DLM 是一次"换状态空间"的尝试,但它不是这条路线的终点;真正重要的是把"什么是更好的文本表征"这个问题持续推下去。
按上面的分析,至少有四条值得做的方向:
- 更强的 representation module。VAE 可以换成 stronger AE / RAE / BERT 或 T5 style semantic encoder / sentence 或 discourse 级 encoder / multilingual shared semantic encoder。表征的好坏是这条路线的天花板。
- 更优秀的 compression。Patch 实验告诉我们 token-level 不是终点。Adaptive segmentation、learned boundary、phrase / event chunking、hierarchical latent pyramid,都值得严肃做。
- 更系统的 logSNR / noise / dim / block 协同 calibration。它们不是独立超参,而是共同作用在同一条"语义信息曲线"上。需要更系统的理论和工具去校准这条曲线。
- 更强 / 更通用的 prior。Flow Matching 是好的 solver,但不是唯一选择;CNF、rectified flow、shortcut / consistency model、autoregressive latent prior、hybrid continuous-discrete prior 都值得放上桌面对比。
注意,这里我特意不把 diffusion 列为重点方向,因为它从来不是这条路线的核心。它只是因为很合适,所以现在用它。
十七、Unified:encoder = 感受器,DiT = 脑,decoder = 动作器
这一节我想短一点说——unified 是 Cola DLM 的一个附加价值,不是 motivation 本身;它真正重要的不是技术 demo,而是背后的一种思考视角。
为什么 unified 重要?我倾向于从"模型与环境的交互"这个视角来看。把学习系统抽象成环境:
其中 $\mathcal{O}$ 是观察空间、$\mathcal{A}$ 是动作 / 输出空间、$\mathcal{T}$ 是状态转移、$\mathcal{F}$ 是反馈生成机制、$\mathcal{G}$ 是把反馈转化成优化信号的规则。真实环境里 observation 是多模态的:
如果存在一个 joint latent state $z_t = \Phi(o_t^{(1)}, \dots, o_t^{(M)})$,使得反馈和转移主要依赖这个 joint state,而不能拆成各模态独立的乘积:
那这件事就是结构上不可分的——把不同模态简单拼到一个 backbone 上不够,模型需要在一个共享 latent interaction space 里学 joint regularities。
而长期以来 unified modeling 卡住的核心障碍之一,就是文本是离散的,图像、视频、音频天然偏连续。如果想让它们进入同一个 latent world state,必须有一个把文本映射到连续语义 latent 的接口。Cola DLM 正好提供这个接口:
之后可以与图像 / 视频 / 音频 latent 组成
由一个 shared block-causal prior 在 latent 上组织 cross-modal 状态,再由各模态 decoder 实现具体 output。从 ELBO 角度看,这种 unified 写法和 text-only 的分解一脉相承:
也就是说,unified modeling 不是把多模态塞进一个 backbone,而是在异质观测上共享一个语义先验。
我喜欢一种直观比喻:
- Encoder = 感受器,把外部环境映射进 latent;
- DiT / prior model = 脑,在 latent 上组织语义和动态;
- Decoder = 动作器,把内部状态实现为 text / image / video / audio / action 等具体输出。
paper 也展示了 Cola DLM 在 unified 上的可行性 demo:text-only continuation、image-conditioned text、text-to-image 在同一框架内的联合训练(虽然规模和 finetune 都还是早期)。

这里有一个更宏观的观点想说出来:接下来语言模型的演化重点,不应只在"模型如何与环境交互"上做技巧(各种 RL、distillation、reward shaping),更要扩展"模型与环境交互的模态"本身。前者是在固定模态接口下卷优化方法,后者是在重塑模型能"看到"和"动用"的世界结构。Cola DLM 的 text latent 接口,在我看来更接近后者。
十八、结语:Representation > Diffusion
这里做一些小小的总结,我们知道 paper 的相关内容或许存在很多不够完善的地方,大家轻喷,但也希望大家能够广泛讨论,给出批评意见,这将有助于我们的后续工作!
- Cola DLM 的核心问题不是"diffusion 能不能生成文本",而是"什么是语言智能更好的表征"。
- Token 是语言的表层载体,不一定是最优 state。不同语言、不同 paraphrase 背后的共享语义就是最直接的反例。
- 分层 latent + 连续表征 + diffusion prior 是这条路线的自然组合:分层是为了把全局语义和局部 realization 拆开,连续是因为语义本身具有几何,diffusion / FM 只是建模这种连续 prior 的 solver。
- RQ1 的 timeshift drift 实验反证了"纯局部可分 latent"假设,支持 latent 中存在跨维度共享的语义结构。
- PPL 不再是这种范式下自然的评价语言;representation 一旦换了,evaluation language 也得跟着换。
- Patch 实验提示 token-level 切分可能不是最优粒度,未来一定会出现语义承载更高效的更强表征形态,这也是 MTP 在更高层次上想回答的问题。
- Unified 不是把多模态塞进一个 backbone,而是让模型在一个结构非可分的环境里学习;Cola DLM 的 text latent 是离散文本进入连续多模态交互的一座桥。
最后用一句话收尾——下一代 language model 不必永远被 next-token prediction 定义。它可以是、也应该是某种 representation-centric 的范式。Cola DLM 只是这条路上的一次早期尝试,但这条路本身值得继续走下去。
代码和模型本周也会发布并整合到 transformers 库,并开源,欢迎关注项目首页的相关信息!再次感谢社区的关注,我们也非常期待大家的讨论与指教。